Usage Background
1. Project Background
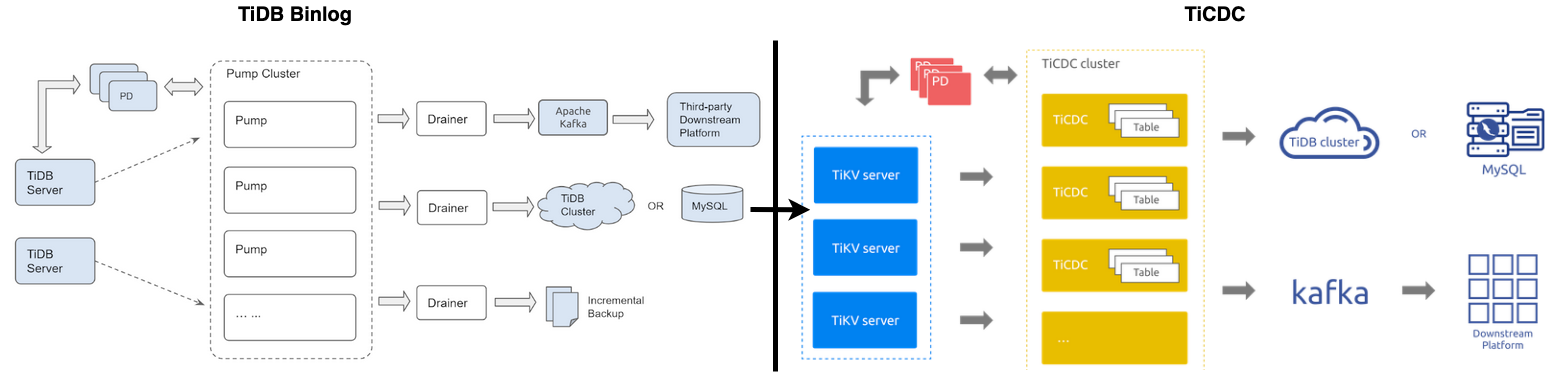
As described on the PingCAP official website, the main use cases of TiCDC are "database disaster recovery" and "data integration". Enthusiasts familiar with the TiDB ecosystem might know about "TiDB Binlog", a tool with similar functionality to TiCDC. So why reinvent the wheel?
The answer lies in the limitations of "TiDB Binlog," which cannot address the following (not exhaustive) issues. For those unfamiliar with "TiDB Binlog," refer to the TiDB Binlog Overview:
- Poor scalability of "TiDB Binlog," such as the "single point" and "performance" issues of Drainer. Splitting Drainer cannot ensure "row change order."
- Low performance of "TiDB Binlog," such as only supporting single Kafka single partition writes, which limits Kafka throughput.
- Poor generality of "TiDB Binlog," such as requiring Reparo to parse SQL statements when writing binlog files, and not supporting general protocols like Maxwell or Canal.
- Synchronization pain points of "TiDB Binlog," such as being limited by GRPC max message size, e.g., Pump's gRPC message exceeds limit.
- Poor availability of "TiDB Binlog," such as synchronization interruptions when the single-point Drainer fails, with no self-healing capabilities.
Thus, TiCDC was born. By directly capturing TiKV Change Logs, TiCDC uses tables as split units to schedule data synchronization to various Captures, solving scalability issues. It supports multi-partition Kafka writes and general protocols like Maxwell and Canal, addressing synchronization performance and ecosystem compatibility issues. When synchronization times out, Capture has uneven table distribution, or Capture crashes, TiCDC's scheduling mechanism and "At Least Once" guarantee ensure data integrity and self-healing.
2. Tool Position
To understand how to use TiCDC, one must first clarify its position and role in the TiDB ecosystem.
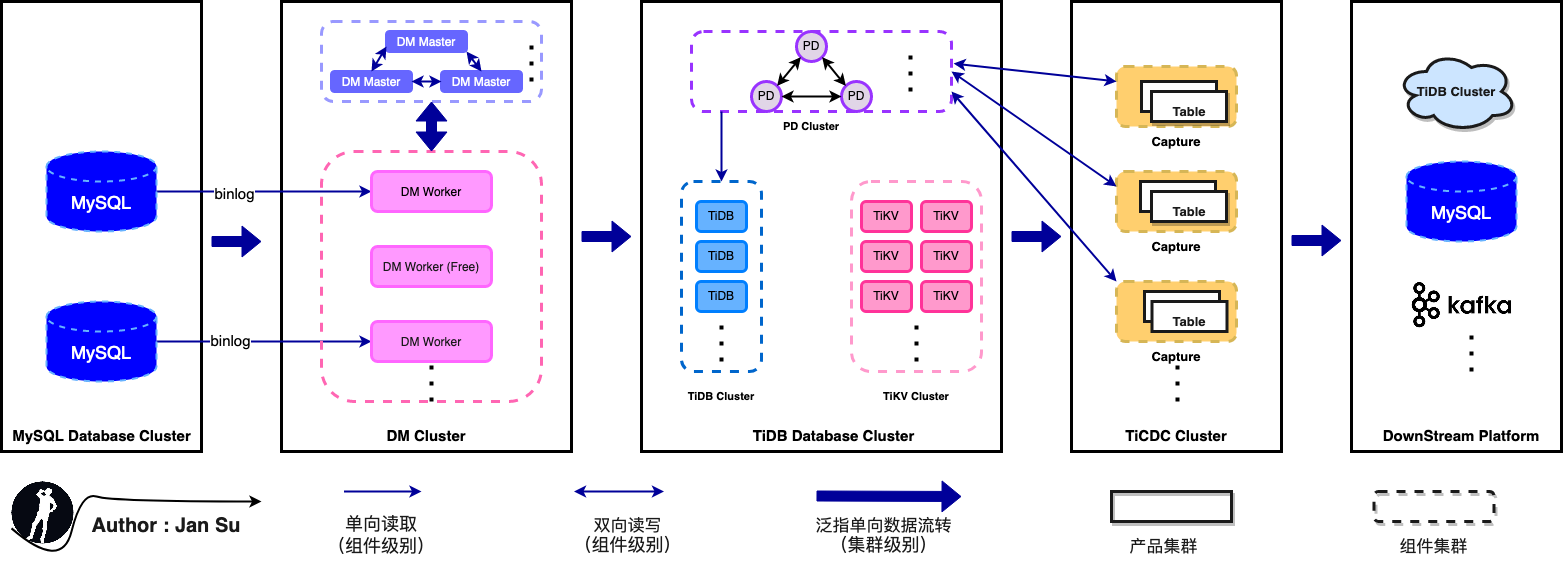
1. In terms of role: If a database is a "one-way street," it will inevitably be abandoned by the market, becoming a so-called "data island." TiCDC balances synchronization performance, data integrity, consistency, and ecosystem compatibility, creating a closed loop of "data inflow -> TiDB -> data outflow." Additionally, discussing performance without considering scenarios is meaningless. No product can excel in all scenarios, and TiDB has its comfort zones and pain points. With TiCDC, users can easily enable data flow and use TiDB in its optimal scenarios.
2. In terms of position: TiCDC sits between TiDB and downstream destinations, which include all products and platforms compatible with MySQL communication protocols (e.g., TiDB, MySQL, RDS, third-party cloud platforms). Users can also develop custom solutions based on general message queue output protocols. Currently, TiCDC supports protocols like Open Protocol, Canal-JSON, Canal, Avro, and Maxwell. Some protocols are only partially supported. For details, refer to --> TiCDC Supported Protocols Guide.
Additionally, TiCDC covers almost all mainstream "data synchronization" use cases. The diagram below illustrates the classic combination of "MySQL --> TiDB --> Others." For other protocol databases (Oracle, PG), the method to flow into TiDB is equivalent to flowing into MySQL, as TiDB is compatible with MySQL communication protocols, ensuring mature solutions exist.
3. Usage Scenarios
Note: The following companies were identified through articles on AskTUG, where shared articles mentioned their use of TiCDC. These companies are only those discoverable through search. Many commercial customers either request confidentiality or have not yet disclosed their usage.
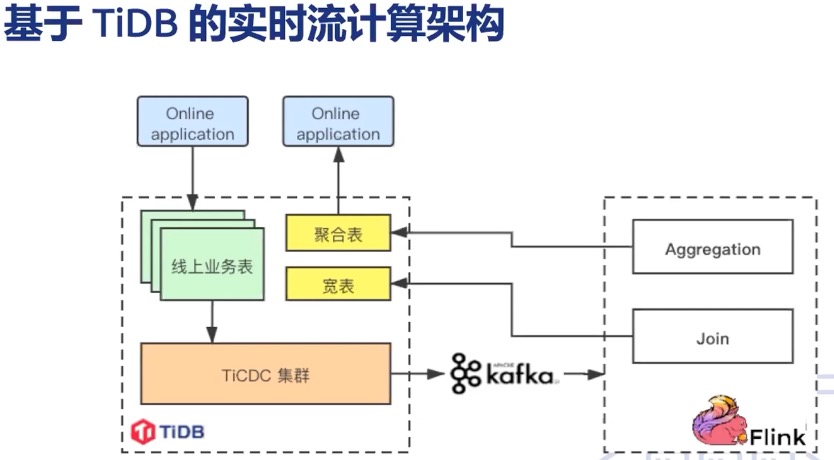
3.1 Xiaohongshu
From Zhang Yihao's sharing in 【PingCAP Infra Meetup】No.131 TiCDC's Ecosystem and Community Development, Xiaohongshu uses TiCDC for content review, note tag recommendations, and growth audits. The architecture is as follows: "TiDB --> TiCDC --> Kafka --> Flink --> TiDB," enabling aggregation with other data sources.
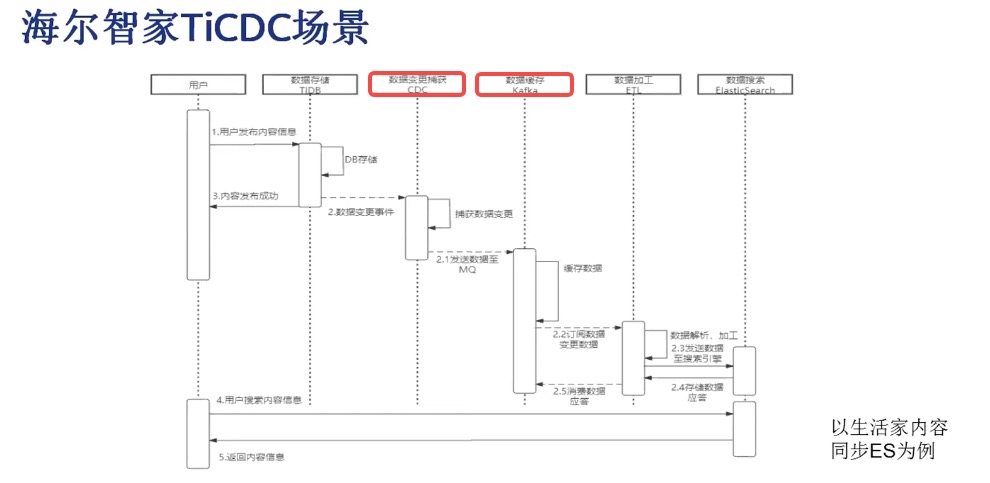
3.2 Haier Smart Home
From Yao Xiang's sharing in 【PingCAP Infra Meetup】No.131 TiCDC's Ecosystem and Community Development, Haier Smart Home uses TiCDC for search and recommendations. User data and smart home information are processed through "TiDB --> TiCDC --> Kafka --> ES," achieving near real-time search functionality with Kafka consuming approximately 3 million messages daily. As of the 2019-09-19 sharing, TiCDC's synchronization boundary under normal conditions is in the "millisecond" range, and under jitter conditions, it is within "seconds" (less than 10s).
Additionally, from Github -- Question and Bug Reports, TiCDC has a roadmap for improving synchronization performance, such as mqSink flushes data synchronously, causing low performance and improve performance of syncer. TiCDC's synchronization performance is a continuous optimization process.
3.3 360
From Dai Xiaolei's sharing in BLOG - TiCDC Application Scenarios Analysis, 360 uses TiCDC to meet the needs of incremental data extraction, same-city dual-cluster hot backup, and stream processing.
4. Usage Methods
4.1 Deploying TiCDC
The following test environment sets up TiCDC for testing and learning its synchronization capabilities. The CDC components on 172.16.6.155:8300 and 172.16.6.196:8300 will appear after scaling.
[tidb@Linux-Hostname ~]$ tiup cluster display tidb-test
ID Role Host Ports OS/Arch Status Data Dir Deploy Dir
-- ---- ---- ----- ------- ------ -------- ----------
172.16.6.155:9093 alertmanager 172.16.6.155 9093/9094 linux/x86_64 Up /home/data/tidb-home/data/alertmanager-9093 /home/data/tidb-deploy/alertmanager-9093
172.16.6.155:8300 cdc 172.16.6.155 8300 linux/x86_64 Up /data/deploy/install/data/cdc-8300 /home/data/tidb-deploy/cdc-8300
172.16.6.196:8300 cdc 172.16.6.196 8300 linux/x86_64 Up /data/deploy/install/data/cdc-8300 /home/data/tidb-deploy/cdc-8300
172.16.6.155:3000 grafana 172.16.6.155 3000 linux/x86_64 Up - /home/data/tidb-deploy/grafana-3000
172.16.6.155:2379 pd 172.16.6.155 2379/2380 linux/x86_64 Up|UI /home/data/tidb-home/data/pd-2379 /home/data/tidb-deploy/pd-2379
172.16.6.194:2379 pd 172.16.6.194 2379/2380 linux/x86_64 Up /home/data/tidb-home/data/pd-2379 /home/data/tidb-deploy/pd-2379
172.16.6.196:2379 pd 172.16.6.196 2379/2380 linux/x86_64 Up|L /home/data/tidb-home/data/pd-2379 /home/data/tidb-deploy/pd-2379
172.16.6.155:9090 prometheus 172.16.6.155 9090/12020 linux/x86_64 Up /home/data/tidb-home/data/prometheus-9090 /home/data/tidb-deploy/prometheus-9090
172.16.6.155:4000 tidb 172.16.6.155 4000/10080 linux/x86_64 Up - /home/data/tidb-deploy/tidb-4000
172.16.6.196:4000 tidb 172.16.6.196 4000/10080 linux/x86_64 Up - /home/data/tidb-deploy/tidb-4000
172.16.6.155:20160 tikv 172.16.6.155 20160/20180 linux/x86_64 Up /home/data/tidb-home/data/tikv-20160 /home/data/tidb-deploy/tikv-20160
172.16.6.194:20160 tikv 172.16.6.194 20160/20180 linux/x86_64 Up /home/data/tidb-home/data/tikv-20160 /home/data/tidb-deploy/tikv-20160
172.16.6.196:20160 tikv 172.16.6.196 20160/20180 linux/x86_64 Up /home/data/tidb-home/data/tikv-20160 /home/data/tidb-deploy/tikv-20160TiCDC reached GA in version 4.0.6, and it is recommended to use version 4.0.6 and above. For details, refer to the --> TiCDC Official Documentation. The scaling steps are as follows.
[tidb@Linux-Hostname ~]$ cat scale-out-cdc.yaml
cdc_servers:
- host: 172.16.6.155
gc-ttl: 86400
data_dir: /data/deploy/install/data/cdc-8300
- host: 172.16.6.196
gc-ttl: 86400
data_dir: /data/deploy/install/data/cdc-8300
[tidb@Linux-Hostname ~]$ tiup cluster scale-out tidb-test scale-out-cdc.yaml4.2 Synchronization to Kafka
As I had no prior experience with Kafka, I referred to the Kafka Quickstart to set up a Kafka environment on 172.16.6.155 and 172.16.6.196 for testing. The goal was to parse messages sent to Kafka by TiCDC.
# Install Java Runtime Environment
[tidb@kafka1 ~]$ yum install java-1.8.0-openjdk.x86_64
[tidb@kafka1 ~]$ java -version
openjdk version "1.8.0_322"
# Set up Kafka on 172.16.6.155 and 172.16.6.196
[tidb@kafka1 ~]$ wget https://dlcdn.apache.org/kafka/3.1.0/kafka_2.13-3.1g/kafka/3.1.0/kafka_2.13-3.1.0.tgz --no-check-certificate
[tidb@kafka1 ~]$ tar -xzf kafka_2.13-3.1.0.tgz
[tidb@kafka1 ~]$ cd kafka_2.13-3.1.0
[tidb@kafka1 ~]$ bin/zookeeper-server-start.sh config/zookeeper.properties
[tidb@kafka1 ~]$ bin/kafka-server-start.sh config/server.properties
# Create a topic named tidb-test with 2 partitions
[tidb@kafka1 ~]$ bin/kafka-topics.sh --create --topic tidb-test \
--bootstrap-server 172.16.6.155:9092,172.16.6.196:9092 \
--partitions 2
Created topic quickstart-events.
# Describe the tidb-test topic to verify its configuration
[tidb@kafka1 ~]$ bin/kafka-topics.sh --describe --topic tidb-test \
--bootstrap-server 172.16.6.155:9092,172.16.6.196:9092
Topic: tidb-test TopicId: OjM6FFrBQtqyEB4sVWmYCQ PartitionCount: 2 ReplicationFactor: 1 Configs: segment.bytes=1073741824
Topic: tidb-test Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic: tidb-test Partition: 1 Leader: 0 Replicas: 0 Isr: 0
# Create a changefeed in TiCDC to synchronize data to Kafka, using the manually created tidb-test topic
[tidb@kafka1 ~]$ tiup cdc cli changefeed create --pd=http://172.16.6.155:2379 \
--sink-uri="kafka://172.16.6.155:9092/tidb-test?protocol=canal-json&kafka-version=2.4.0&partition-num=2&max-message-bytes=67108864&replication-factor=1"
tiup is checking updates for component cdc ...
Starting component `cdc`: /home/tidb/.tiup/components/cdc/v6.0.0/cdc /home/tidb/.tiup/components/cdc/v6.0.0/cdc cli changefeed create --pd=http://172.16.6.155:2379 --sink-uri=kafka://172.16.6.155:9092/tidb-test?protocol=canal-json&kafka-version=2.4.0&partition-num=2&max-message-bytes=67108864&replication-factor=1
[2022/05/12 16:37:09.667 +08:00] [WARN] [kafka.go:416] ["topic's `max.message.bytes` less than the `max-message-bytes`,use topic's `max.message.bytes` to initialize the Kafka producer"] [max.message.bytes=1048588] [max-message-bytes=67108864]
[2022/05/12 16:37:09.667 +08:00] [WARN] [kafka.go:425] ["topic already exist, TiCDC will not create the topic"] [topic=tidb-test] [detail="{\"NumPartitions\":2,\"ReplicationFactor\":1,\"ReplicaAssignment\":{\"0\":[0],\"1\":[0]},\"ConfigEntries\":{\"segment.bytes\":\"1073741824\"}}"]
Create changefeed successfully!
......
# Use sysbench to insert 2 rows into jan.sbtest1
[tidb@kafka1 ~]$ sysbench oltp_read_write --mysql-host=127.0.0.1 \
--mysql-port=4000 \
--mysql-db=jan \
--mysql-user=root \
--mysql-password= \
--table_size=2 \
--tables=1 prepare
# Parse the data changes in Kafka as follows
[tidb@kafka1 ~]$ bin/kafka-console-consumer.sh --topic tidb-test \
--from-beginning --bootstrap-server 172.16.6.155:9092,172.16.6.196:9092
{"id":0,"database":"jan","table":"sbtest1","pkNames":["id"],"isDdl":false,"type":"INSERT","es":1652344970654,"ts":1652344977538,"sql":"","sqlType":{"c":1,"id":4,"k":4,"pad":1},"mysqlType":{"c":"char","id":"int","k":"int","pad":"char"},"data":[{"c":"83868641912-28773972837-60736120486-75162659906-27563526494-20381887404-41576422241-93426793964-56405065102-33518432330","id":"1","k":"1","pad":"67847967377-48000963322-62604785301-91415491898-96926520291"}],"old":null}
{"id":0,"database":"jan","table":"sbtest1","pkNames":["id"],"isDdl":false,"type":"INSERT","es":1652344970654,"ts":1652344977538,"sql":"","sqlType":{"c":1,"id":4,"k":4,"pad":1},"mysqlType":{"c":"char","id":"int","k":"int","pad":"char"},"data":[{"c":"38014276128-25250245652-62722561801-27818678124-24890218270-18312424692-92565570600-36243745486-21199862476-38576014630","id":"2","k":"2","pad":"23183251411-36241541236-31706421314-92007079971-60663066966"}],"old":null}
{"id":0,"database":"jan","table":"","pkNames":null,"isDdl":true,"type":"QUERY","es":1652344966953,"ts":1652344969305,"sql":"CREATE DATABASE `jan`","sqlType":null,"mysqlType":null,"data":null,"old":null}
{"id":0,"database":"jan","table":"sbtest1","pkNames":null,"isDdl":true,"type":"CREATE","es":1652344970604,"ts":1652344975305,"sql":"CREATE TABLE `sbtest1` (`id` INT NOT NULL AUTO_INCREMENT,`k` INT DEFAULT _UTF8MB4'0' NOT NULL,`c` CHAR(120) DEFAULT _UTF8MB4'' NOT NULL,`pad` CHAR(60) DEFAULT _UTF8MB4'' NOT NULL,PRIMARY KEY(`id`)) ENGINE = innodb","sqlType":null,"mysqlType":null,"data":null,"old":null}
{"id":0,"database":"jan","table":"sbtest1","pkNames":null,"isDdl":true,"type":"CINDEX","es":1652344973455,"ts":1652344978504,"sql":"CREATE INDEX `k_1` ON `sbtest1` (`k`)","sqlType":null,"mysqlType":null,"data":null,"old":null}
# Clean up the Kafka environment set up on 172.16.6.155 and 172.16.6.196
# First, use ctrl + c to close all foreground processes started in terminals
[tidb@kafka1 ~]$ rm -rf /tmp/kafka-logs /tmp/zookeeper4.3 Synchronization to MySQL
To synchronize data to MySQL, install MySQL on 172.16.6.155:3306. After configuring the relevant parameters, a subscription task with the ID simple-replication-task can be created. The synchronization progress can be monitored on the Grafana dashboard. MySQL is a familiar tool for DBAs, so the steps for verifying synchronization are not elaborated here.
[tidb@Linux-Hostname ~]$ tiup cdc cli changefeed create --pd=http://172.16.6.155:2379 \
--sink-uri="mysql://jan:123123@172.16.6.155:3306/?time-zone=&worker-count=16&max-txn-row=5000" \
--changefeed-id="simple-replication-task" \
--sort-engine="unified" \
--config=changefeed.toml
tiup is checking updates for component cdc ...
Starting component `cdc`: /home/tidb/.tiup/components/cdc/v6.0.0/cdc /home/tidb/.tiup/components/cdc/v6.0.0/cdc cli changefeed create --pd=http://172.16.6.155:2379 --sink-uri=mysql://jan:123123@172.16.6.155:3306/?time-zone=&worker-count=16&max-txn-row=5000 --changefeed-id=simple-replication-task --sort-engine=unified --config=changefeed.toml
[2022/04/12 16:58:40.954 +08:00] [WARN] [mysql_params.go:143] ["max-txn-row too large"] [original=5000] [override=2048]
Create changefeed successfully!
......5. Referenced Articles
1. 【PingCAP Infra Meetup】No.131 Why and how we build TiCDC
2. 【PingCAP Infra Meetup】No.131 TiCDC 的生态和社区建设3. 官方文档 -- TiCDC
4. 官方文档 -- TiDB Binlog
5. 官方 FAQ -- Pump 的 gRPC message 超过限值
6. Github Design Doc -- TiCDC 支持的消息队列输出协议指南
7. Github Question and Bug Reports -- TiCDC 提升性能规划路径
8. AskTUG Blog -- 代晓磊 TiCDC 应用场景解析
9. 官方文档 -- Kafka
Additionally, AskTUG, as the official support community for the TiDB ecosystem, is recommended for discussions here https://tidb.net/blog/70588c4c.